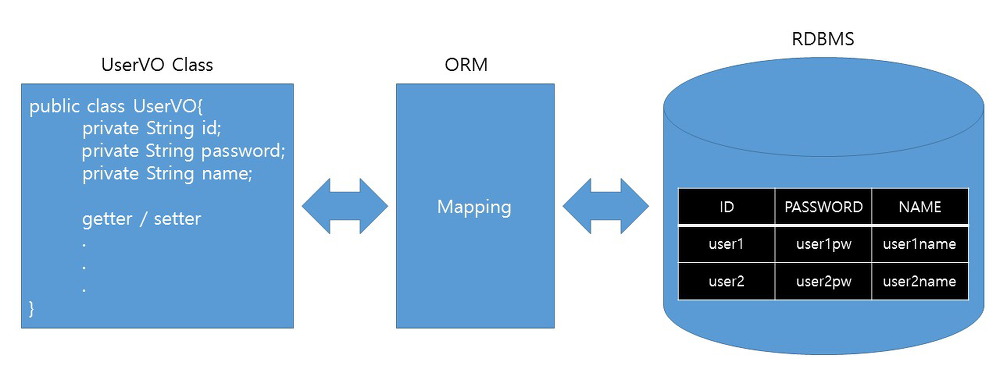
Entity먼저 데이터베이스에 저장하기 위해 유저가 정의한 클래스가 필요한데 그런 클래스를
Entity라고 한다. Domain이라고 생각하면 된다.
일반적으로 RDBMS에서 Table을 객체화 시킨 것으로 보면 된다.
그래서 Table의 이름이나 컬럼들에 대한 정보를 가진다.
/**
* Created by Itner on 2017. 7. 20..
*/
@Entity
public class Member {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private long id;
@Column
private String name;
@Column
private int age;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
@Id
primary key를 가지는 변수를 선언하는 것을 뜻한다. @GeneratedValue 어노테이션은 해당 Id 값을
어떻게 자동으로 생성할지 전략을 선택할 수 있다. 여기서 선택한 전략은 "AUTO"이다.
@Table
별도의 이름을 가진 데이터베이스 테이블과 매핑한다. 기본적으로 @Entity로 선언된 클래스의 이름은 실제
데이터베이스의 테이블 명과 일치하는 것을 매핑한다. 따라서 @Entity의 클래스명과 데이터베이스의 테이블명이
다를 경우에 @Table(name=" ")과 같은 형식을 사용해서 매핑이 가능하다.
@Column
@Column 선언이 꼭 필요한 것은 아니다. 하지만 @Column에서 지정한 변수명과 데이터베이스의 컬럼명을
서로 다르게 주고 싶다면 @Column(name=" ") 같은 형식으로 작성하면 된다.
그렇지 않은 경우에는 기본적으로 멤버 변수명과 일치하는 데이터베이스 컬럼을 매핑한다.
Repository
Entity클래스를 작성했다면 이번엔 Repository 인터페이스를 만들어야 한다.
스프링부트에서는 Entity의 기본적인 CRUD가 가능하도록 JpaRepository 인터페이스를 제공한다.
/**
* Created by Itner on 2017. 7. 20..
*/
public interface MemberRepository extends JpaRepository<Member, Long> {
}
Spring Data JPA에서 제공하는 JpaRepository 인터페이스를 상속하기만 해도 되며,
인터페이스에 따로 @Repository등의 어노테이션을 추가할 필요가 없다.
JpaRepository를 상속받을 때는 사용될 Entity 클래스와 ID 값이 들어가게 된다.
즉, JpaRepository<T, ID> 가 된다.
그렇게 JpaRepository를 단순하게 상속하는 것만으로 위의 인터페이스는 Entity 하나에 대해서
아래와 같은 기능을 제공하게 된다.
|
method |
기능 |
|
save() |
레코드 저장 (insert, update) |
|
findOne() |
primary key로 레코드 한건 찾기 |
| findAll() |
전체 레코드 불러오기. 정렬(sort), 페이징(pageable) 가능 |
| count() | 레코드 갯수 |
| delete() | 레코드 삭제 |
위의 기본기능을 제외한 조회 기능을 추가하고 싶으면 규칙에 맞는 메서드를 추가해야한다.
/**
* Created by Itner on 2017. 7. 20..
*/
public interface MemberRepository extends JpaRepository<Member, Long> {
Member findByName(String name);
Page<Member> findByName(String name, Pageable pageable);
}
위와 같이 Query 메소드를 추가하여 스프링에게 알릴 수 있다.
그러기위해서는 규칙에 맞는 메서드를 작성해야 하는데, 그 규칙은 다음과 같다.
|
method |
설명 |
|
findBy로 시작 |
쿼리를 요청하는 메서드 임을 알림 |
|
countBy로 시작 |
쿼리 결과 레코드 수를 요청하는 메서드 임을 알림 |
위의 findBy에 이어 해당 Entity 필드 이름을 입력하면 검색 쿼리를 실행한 결과를 전달한다.
SQL의 where절을 메서드 이름을 통해 전달한다고 생각하면 된다.
메서드의 반환형이 Entity 객체이면 하나의 결과만을 전달하고, 반환형이 List라면 쿼리에 해당하는
모든 객체를 전달한다.
Query 메소드에 포함할 수 있는 키워드는 다음과 같다.
|
메서드 이름 키워드 |
샘플 |
설명 |
|
And |
findByEmailAndUserId(String email, String userId) |
여러필드를 and 로 검색 |
|
Or |
findByEmailOrUserId(String email, String userId) |
여러필드를 or 로 검색 |
|
Between |
findByCreatedAtBetween(Date fromDate, Date toDate) |
필드의 두 값 사이에 있는 항목 검색 |
|
LessThan |
findByAgeGraterThanEqual(int age) |
작은 항목 검색 |
|
GreaterThanEqual |
findByAgeGraterThanEqual(int age) |
크거나 같은 항목 검색 |
|
Like |
findByNameLike(String name) |
like 검색 |
|
IsNull |
findByJobIsNull() |
null 인 항목 검색 |
|
In |
findByJob(String … jobs) |
여러 값중에 하나인 항목 검색 |
|
OrderBy |
findByEmailOrderByNameAsc(String email) |
검색 결과를 정렬하여 전달 |
좀 더 자세한 키워드와 쿼리를 보고 싶다면 JPA 레퍼런스를 참고하면 된다.
Pageable
위 코드 중 한가지 설명이 빠진 것이 있는데, 바로 Pageable이다.
Query 메소드의 입력변수로 위와 같이 Pageable 변수를 추가하면 Page타입을 반환형으로 사용할 수 있다.
Pageable 객체를 통해 페이징과 정렬을 위한 파라미터를 전달한다.
Pageable 입력 변수는 아래와 같이 Controller에서부터 전달받아야 한다.
/**
* Created by Itner on 2017. 7. 20..
*/
@RestController
@RequestMapping("/member")
public class MemberController {
@Autowired
MemberService memberService;
@RequestMapping("")
Page<Member> getMembers(Pageable pageable){
return memberService.getList(pageable)
}
}
위와 같이 작성된 Pageable에서는 다음과 같은 파라미터를 자동 수집한다.
|
query parameter 명 |
설명 |
|
page |
몇번째 페이지 인지를 전달 |
|
size |
한 페이지에 몇개의 항목을 보여줄것인지 전달 |
|
sort |
정렬정보를 전달. 정렬정보는 필드이름,정렬방향 의 포맷으로 전달한다. 여러 필드로 순차적으로 정렬도 가능하다.
예: sort=createdAt,desc&sort=userId,asc |
아래는 위 Controller를 통해 HTTP요청으로 페이징과 정렬된 데이터를 전달받는 URI 샘플이다.
GET /users?page=1&size=10&sort=createdAt,desc&sort=userId,asc
이렇게 웹 페이지 개발에 필수적인 정렬과 페이지 정보를 접속 URI에서부터 Repository까지 바로 전달이 가능하다.
'Spring Framework' 카테고리의 다른 글
| [Spring JPA 에러] QuerySyntaxException is not mapped (0) | 2019.07.23 |
|---|---|
| JPA(Java Persistance API) 개념 (0) | 2019.06.24 |
| (STS) Spring Framework-Lombok 설치 (0) | 2019.06.23 |
| Spring MVC 라이프 사이클 (0) | 2019.06.20 |